前言
本文是对“从机器学习谈起.pdf”的笔记。
感兴趣的朋友欢迎加入学习小组QQ群: 193765960。
版权归作者所有,如有转发,请注明文章出处:https://xiaodanchen.github.io/archives/
一个故事说明什么是机器学习
等人问题:
机器学习的定义
机器学习就是计算机利用已有数据,得出某种模型,然后利用该模型预测未来的一种方法。
区别于我们常见的计算机程序基于因果(固定程序方法)的,机器学习是基于经验(数据)的算法。
机器学习的范围
- 模式识别:模式识别=机器学习。模式识别源于工业界,机器学习源于计算机科学,二者是统一问题在两个领域的不同体现。
- 数据挖掘:数据挖掘=机器学习+数据库。
- 统计学习:统计学习近似于机器学习。机器学习的大量方法来自于统计学,区别是,前者偏重于数学领域,后者偏重于实践。
- 计算机视觉:计算机视觉=图像处理+机器学习。图像处理技术将图片处理成时候机器学习算法适用的输入数据,学习算法则根据机器学习模型从输入图像中识别出相关的模式。例如:百度识图,手写输入,车牌识别等。
- 语音识别:语音处理+机器学习。
- 自然语言处理:文本处理+机器学习。
机器学习的方法
回归算法
- 线性回归:数值问题。最小二乘法;数值计算:梯度下降法,牛顿法
例子:预测房价问题。 - 逻辑回归:分类问题。
例子:预测肿瘤问题。神经网络:
ANN(人工神经网络)算法,BP算法(加速神经网络训练过程的数值算法)。神经网络学习的机理简单来说就是“分解与组合”。
下面让我们来看一个简单的神经网络模型:输入层 -> 隐藏层 -> 输出层。输入层负责接收信号数据。隐藏层负责数据的分析和处理,最后将结果整合输出到输出层。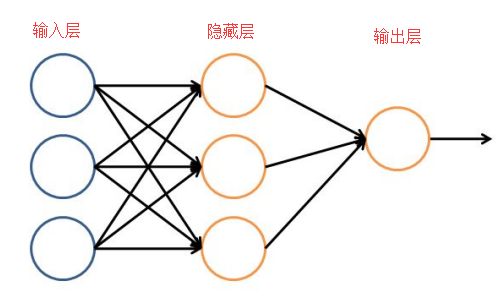
如图:每层中的一个元代表了一个处理单元,模拟了一个神经元。若干个处理单元组成一个层,若干个层组成一个简单的“神经网络”。
在神经网络中,每个处理单元实际上就是一个“逻辑回归模型”。逻辑回归模型接收上一层的输入,把模型的预测结果作为输出传递给下一层。通过这样的过程,神经网络可以实现非常复杂的非线性分类。
进入90年代,神经网络算法进入一个瓶颈期,原因是虽然具有BP算法的加速,神经网络的训练过程仍然很困难。因此90年代后期支持向量机算法(SVM)取代了神经网络的地位。
支持向量机(SVM)算法:
支持向量机算法是但是与统计学习界,同时在机器学习界大放光彩的经典算法。
SVM从某种意义上来说是逻辑回归算法的强化:通过给与逻辑回归算法更加严格的优化条件,SVM可以获得比逻辑回归算法更好的分类界限,从而达成很好的效果。
通过和高斯“核“的结合,SVM可以表达出非常复杂的分类界线。”核”实际上是一种特殊的函数,最典型的特征就是可以将低维的空间映射到高维的空间(但却不会带来计算复杂性的提升)。
SVG一直占据着机器学习最核心的地位,基本取代了神经网络算法,直至近期神经网络接着深度学习重新崛起,两者之间才又发生了微妙的平衡变化。
聚类算法:
前面的算法一个显著的特征就是训练数据中包含了标签,训练出的模型可以对其他数据预测标签,即监督式学习。
在下面的算法中,训练数据是不含标签的,而算法的目的是通过训练,推测这些数据的标签,即无监督算法。
无监督式学习最典型的算法就是聚类算法。比如K-Means算法。
降维(特征量)算法:
降维算法也是一种无监督式学习算法,其特征就是将数据从高位降低到低维层次。
降维算法的主要作用是压缩数据以及提升其他算法的效率。降维算法的另一个好处是可以实现数据的可视化(降维至3维以下)。
降维算法的代表是PCA算法(主成分分析算法)。
推荐算法:
推荐算法是目前非常火的一种算法,在电商领域得到了非常广泛的运用。推荐算法的主要特征就是可以自动向用户推荐他们感兴趣的东西,从而增加购买率,提升效率。
推荐算法有两个主要的类别:
- 基于物品内容的推荐:是将与用户购买的内容相似的物品推荐给用户。这样的前提是每个物品都得有若干个标签,好处是物品关联度较大,缺点是因为每个物品都要贴标签,工作量较大。
- 基于用户相似度的推荐:是将与目标用户兴趣相同的其他用户购买的物品推荐给目标用户。
这两种类别的算法各有优缺点,一般混合使用。最著名的就是协同过滤算法。其他:
除了以上算法外,机器学习领域还有其他算法,例如:高斯判别,朴素贝叶斯算法,决策树等等。但是上面六种是使用最多,影响最广,类型最全的典型算法。
机器学习的应用–大数据
众所周知,现在是大数据的时代。那么,到底什么是大数据呢?实际上,大数据是一门实实在在的有着基础理论和科学研究背景的一门技术,其中包含着分布式计算、内存计算、机器学习、计算机视觉、语音识别、自然语言处理等众多计算机界崭新的技术,而且是这些技术综合的产物。
事实上,大数据包含着4大特征,即4V理念:Volume(体量)、Varity(多样性)、Velocity(速度)、Value(价值)。如图: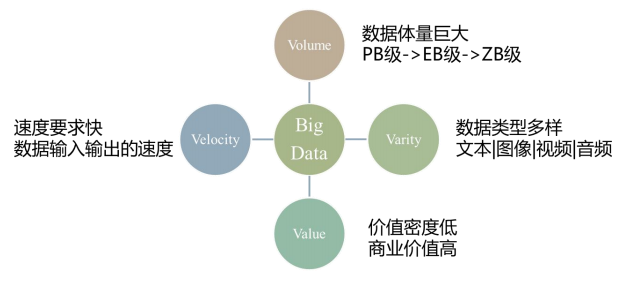
大数据的核心是利用数据的价值,机器学习是利用数据价值的关键技术。同时,复杂的机器学习算法的计算时间迫切需要分布式计算,内存计算这样的关键技术。机器学习与大数据二者是相辅相成,相互促进的关系。
成功的机器学习应用不是拥有最好算法,而是拥有做多的数据。
大数据分布式计算技术Map-Reduce使得计算越来越快。
机器学习的子类–深度学习
进来,机器学习的发展产生了一个新的方向:深度学习。听起来非常高大上,但其原理非常简单,即将传统的神经网络发展到了多隐藏层的地步。
2006年Geoffrey Hinton在《科学》杂志上发表了一片文章,论证了两个观点:
1,多隐藏层的神经网络具有优异的特征学习能力,学习到的特征对数据有更本质的刻画,从而有利于可视化和分类。
2,深度神经网络在训练上的难度,可以通过“逐层初始化”来有效克服。
